Далее по тексту я буду обращаться к своей флешке как к устройству /dev/sdb1. Во избежание потери данных убедитесь, что Вы не просто копируете приведённые тут команды, а адаптируете их к своему окружению.
- Скачать образ установочного диска. Я ставил KUbuntu по ссылке http://www.kubuntu.org/getkubuntu/download
- Создать на флешке раздел размером около 1ГБ (например, с помощью fdisk). Может, размер раздела можно делать и больше, я просто выбрал такой, потому что читал на help.ubuntu.com об именно таком рекомендуемом размере.
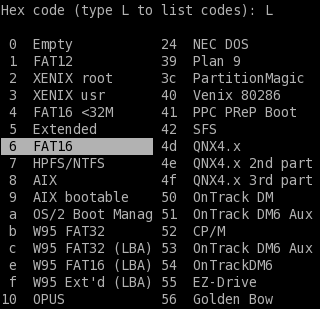 Установить тип файловой системы раздела флешки FAT16 (код 6 в таблице fdisk-а).
Установить тип файловой системы раздела флешки FAT16 (код 6 в таблице fdisk-а).
Я пробовал сначала выбирать "W95 FAT32" для раздела рамером 4ГБ, так в этом случае комп с такой флешки вообще не загрузился, выдавая в начале загрузки сообщение "Disk Error". Не знаю точно в чём именно было тут дело - в размере созданного раздела или в типе системы, но факт остаётся фактом.- Создать файловую систему командой
- Примонтировать файловую систему флешки, например, командой
mount -t vfat /dev/sdb1 /mnt/flashdisk
- Установить программу unetbootin (существует как windows- так и linux-версия, и даже входит в состав репозиториев Fedora Project)
- Запустить unetbootin от имени пользователя root, указать путь к образу диска (iso-файлу), выбрать имя устройства, соответствующего флешке. ПРЕДУПРЕЖДЕНИЕ: если в выпадающем списке "Носитель" Вы не видите своей флешки, то это плохой симптом и может означать, что флешка подготовлена неправильно. Если установить галочку "Показать все носители", то флешку Вы, скорей всего, таки увидите, но вероятность дальнейшей успешной установки ОС с неё весьма невелика.
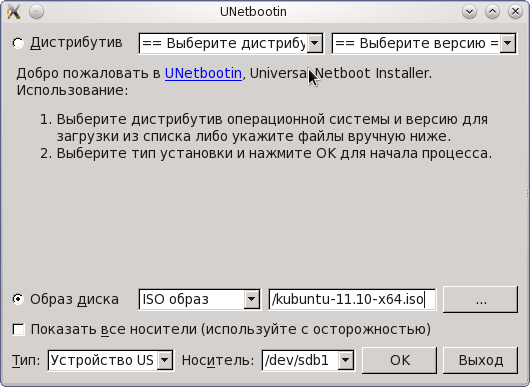
Как создать загрузочную флешку
- Нажать кнопку "OK", подождать пока unetbootin перенесёт на флешку нужные файлы и установит загрузчик.
- Вставить подготовленную флешку в компьютер, на который требуется установить ОС, выбрать в его BIOS-е первым загрузочным устройством флешку, далее как обычно следовать указаниям мастера установки.
Если возникли проблемы с установкой с флешки по вышеописанному алгоритму, то советую почитать раздел "Creating bootable USB manually" на help.ubuntu.com.Там же описаны причины возможных проблем.
UPDATE от 2020-06-03. Unetbootin в Fedora 29 у меня работать отказался, показывая просто белое пустое окно. Поэтому было был нагуглен заменитель - open-source приложение Etcher. С ним всё прошло четко, на 2GB-флешку образ Fedora Workstation 32 записался нормально и потом с этой же флешки установка на ноутбук прошла успешно.
Также видел упоминания о похожей софтинке gnome-multi-writer, но потестить пока не довелось, поскольку Etcher со своей задачей справился отлично.