Инфографику предоставила Wrike - Управление Временем Проекта

Нотатки про Linux та корисні поради для системних адміністраторів
Инфографику предоставила Wrike - Управление Временем Проекта
Posted in Misc.
rev="post-1823" No comments
– 04.04.2018
Binlist.net запилили API, теперь можно удобно узнать банк, выпустивший карту, по её номеру (достаточно первых 6-ти цифр):
$ bin="536354" ; curl -s -H "Accept-Version: 3" "https://lookup.binlist.net/$bin" | jq "."
{
"number": {},
"scheme": "mastercard",
"type": "credit",
"brand": "New World",
"country": {
"numeric": "804",
"alpha2": "UA",
"name": "Ukraine",
"emoji": "🇺🇦",
"currency": "UAH",
"latitude": 49,
"longitude": 32
},
"bank": {
"name": "COMMERCIAL BANK PRIVATBANK",
"url": "old.privatbank.ua",
"phone": "380 562 390 000"
}
}
Частота запросов лимитирована, допускается не более 2 шт в секунду. В случае превышения лимитов сервер вернет код ответа HTTP 429. Если нужно чаще – можно запросить платный доступ.
Стоит отметить, что база у этого сервиса не совсем полная и актуальная. Например, по состоянию на март 2019-го по BIN-у 537541 (карта монобанка) он ничего не выдал, в то время как другой сервис всё показал правильно:
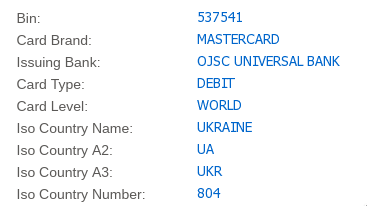
Posted in Misc.
rev="post-1821" No comments
– 30.03.2018
Встречайте – еще один public DNS с IP-адресом 1.1.1.1, на этот раз от Cloudflare. Из Киева до него пинг всего 1 мс (против 30 сек до широкоизвестных гугловых 8.8.8.8 и 8.8.4.4).
Итого список легко запоминающихся DNS-серверов выглядит теперь примерно так:
Кстати, тут написано, что Cloudflare также обеспечивает функционирование E и F корневых DNS-серверов. Кросавчеги.
А еще они подключены к украинской точке обмена трафиком в Киеве на Гайдара 50:
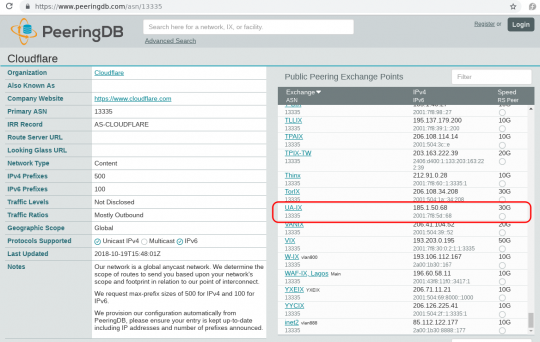
Публичные точки обмена трафиком, с которыми пирится CloudFlare
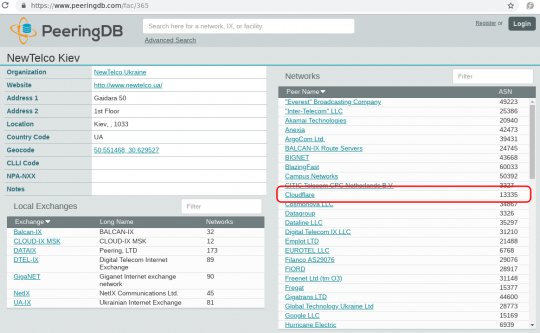
Клаудфларовская AS13335 в списке участников точки обмена трафиком на Гайдара 50
Posted in Misc.
rev="post-1819" No comments
– 29.03.2018
Инфографику предоставила Wrike - Управление Инновационным Проектом

Posted in Misc.
rev="post-1811" No comments
– 06.03.2018
