Зачетный каммент сегодня попался на глаза в статье про новый DHCP-сервер на OpenNet :)
Лучший каммент про DHCP
Нотатки про Linux та корисні поради для системних адміністраторів
Зачетный каммент сегодня попался на глаза в статье про новый DHCP-сервер на OpenNet :)
Лучший каммент про DHCP
rev="post-1657" No comments
– 05.10.2016
Установка RT
Когда количество нехватающих модулей снизилось до четырех вот этих с пометкой MISSING
# perl sbin/rt-test-dependencies perl: >=5.10.1(5.10.1) ...found users: rt group (rt) ...found bin owner (root) ...found libs owner (root) ...found libs group (bin) ...found web owner (apache) ...found web group (apache) ...found CLI dependencies: CORE dependencies: HTML::FormatText::WithLinks::AndTables ...MISSING HTML::Mason::PSGIHandler >= 0.52 ...MISSING HTML::FormatText::WithLinks >= 0.14 ...MISSING Plack::Handler::Starlet ...MISSING DASHBOARDS dependencies: GD dependencies: GPG dependencies: GRAPHVIZ dependencies: ICAL dependencies: MAILGATE dependencies: SMIME dependencies: USERLOGO dependencies: SOME DEPENDENCIES WERE MISSING. CORE missing dependencies: HTML::FormatText::WithLinks >= 0.14 ...MISSING HTML::Mason::PSGIHandler >= 0.52 ...MISSING HTML::FormatText::WithLinks::AndTables ...MISSING Plack::Handler::Starlet ...MISSING Perl library path for /usr/bin/perl: /usr/local/lib64/perl5 /usr/local/share/perl5 /usr/lib64/perl5/vendor_perl /usr/share/perl5/vendor_perl /usr/lib64/perl5 /usr/share/perl5
я с прискорбием осознал, что дальше дело не двигается. Yum-ом их найти не удалось, а perl -MCPAN -e shell ругался малопонятными матюками и тоже отказывался что-либо устанавливать. Так, модуль Plack::Handler::Starlet хотел Server::Starter, Server::Starter хотел Net::EmptyPort, Net::EmptyPort хотел IO::Socket::IP, а IO::Socket::IP при попытке установки выдавал грусть-печальное
Socket version 1.97 required--this is only version 1.82 at /root/.cpan/build/IO-Socket-IP-0.37-nWpYmj/blib/lib/IO/Socket/IP.pm line 30.
Ушел гуглить и таки понял, что я не единственный, к счастью, кто столкнулся с такой бедой. Тадам! Запомните эту магическую командочку:
perl -MCPAN -e 'CPAN::Shell->install(CPAN::Shell->r)'
Судя по man-у, оно делает рекомпиляцию динамически загружаемых модулей CPAN-а, что-то там попутно обновляя. Колбасило долго, где-то с пол-часа, и в конце концов выдало не шибко оптимистичную простыню:
Running install for module 'Thread' The most recent version "3.04" of the module "Thread" is part of the perl-5.24.0 distribution. To install that, you need to run force install Thread --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'Tie::Array' The most recent version "1.06" of the module "Tie::Array" is part of the perl-5.24.0 distribution. To install that, you need to run force install Tie::Array --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'Tie::Hash' The most recent version "1.05" of the module "Tie::Hash" is part of the perl-5.24.0 distribution. To install that, you need to run force install Tie::Hash --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'Tie::Hash::NamedCapture' The most recent version "0.09" of the module "Tie::Hash::NamedCapture" is part of the perl-5.24.0 distribution. To install that, you need to run force install Tie::Hash::NamedCapture --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'Tie::Scalar' The most recent version "1.04" of the module "Tie::Scalar" is part of the perl-5.24.0 distribution. To install that, you need to run force install Tie::Scalar --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'Tie::StdHandle' The most recent version "4.4" of the module "Tie::StdHandle" is part of the perl-5.24.0 distribution. To install that, you need to run force install Tie::StdHandle --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Time::Zone is up to date (2.24). Tree::Simple::Visitor is up to date (1.29). Running install for module 'UNIVERSAL' The most recent version "1.13" of the module "UNIVERSAL" is part of the perl-5.24.0 distribution. To install that, you need to run force install UNIVERSAL --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'Unicode::UCD' The most recent version "0.64" of the module "Unicode::UCD" is part of the perl-5.24.0 distribution. To install that, you need to run force install Unicode::UCD --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'XML::Parser::Expat' Running make for T/TO/TODDR/XML-Parser-2.44.tar.gz Has already been unwrapped into directory /home/avz/.cpan/build/XML-Parser-2.44-TDESRf Could not make: Unknown error Warning (usually harmless): 'YAML' not installed, will not store persistent state Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'attributes' The most recent version "0.27" of the module "attributes" is part of the perl-5.24.0 distribution. To install that, you need to run force install attributes --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible autodie::exception is up to date (2.29). autodie::exception::system is up to date (2.29). autodie::hints is up to date (2.29). bigint is up to date (0.43). bigrat is up to date (0.43). Running install for module 'blib' The most recent version "1.06" of the module "blib" is part of the perl-5.24.0 distribution. To install that, you need to run force install blib --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'bytes' The most recent version "1.05" of the module "bytes" is part of the perl-5.24.0 distribution. To install that, you need to run force install bytes --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'charnames' The most recent version "1.43" of the module "charnames" is part of the perl-5.24.0 distribution. To install that, you need to run force install charnames --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'diagnostics' The most recent version "1.34" of the module "diagnostics" is part of the perl-5.24.0 distribution. To install that, you need to run force install diagnostics --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'feature' The most recent version "1.42" of the module "feature" is part of the perl-5.24.0 distribution. To install that, you need to run force install feature --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible fields is up to date (2.23). Running install for module 'filetest' The most recent version "1.03" of the module "filetest" is part of the perl-5.24.0 distribution. To install that, you need to run force install filetest --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'integer' The most recent version "1.01" of the module "integer" is part of the perl-5.24.0 distribution. To install that, you need to run force install integer --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'less' The most recent version "0.03" of the module "less" is part of the perl-5.24.0 distribution. To install that, you need to run force install less --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'locale' The most recent version "1.09" of the module "locale" is part of the perl-5.24.0 distribution. To install that, you need to run force install locale --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'mro' The most recent version "1.18" of the module "mro" is part of the perl-5.24.0 distribution. To install that, you need to run force install mro --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'open' The most recent version "1.10" of the module "open" is part of the perl-5.24.0 distribution. To install that, you need to run force install open --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'overload' The most recent version "1.26" of the module "overload" is part of the perl-5.24.0 distribution. To install that, you need to run force install overload --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'overloading' The most recent version "0.02" of the module "overloading" is part of the perl-5.24.0 distribution. To install that, you need to run force install overloading --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 're' The most recent version "0.32" of the module "re" is part of the perl-5.24.0 distribution. To install that, you need to run force install re --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'sigtrap' The most recent version "1.08" of the module "sigtrap" is part of the perl-5.24.0 distribution. To install that, you need to run force install sigtrap --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'sort' The most recent version "2.02" of the module "sort" is part of the perl-5.24.0 distribution. To install that, you need to run force install sort --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'strict' The most recent version "1.11" of the module "strict" is part of the perl-5.24.0 distribution. To install that, you need to run force install strict --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'subs' The most recent version "1.02" of the module "subs" is part of the perl-5.24.0 distribution. To install that, you need to run force install subs --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'utf8' The most recent version "1.19" of the module "utf8" is part of the perl-5.24.0 distribution. To install that, you need to run force install utf8 --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'vars' The most recent version "1.03" of the module "vars" is part of the perl-5.24.0 distribution. To install that, you need to run force install vars --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'vmsish' The most recent version "1.04" of the module "vmsish" is part of the perl-5.24.0 distribution. To install that, you need to run force install vmsish --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'warnings' The most recent version "1.36" of the module "warnings" is part of the perl-5.24.0 distribution. To install that, you need to run force install warnings --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Running install for module 'warnings::register' The most recent version "1.04" of the module "warnings::register" is part of the perl-5.24.0 distribution. To install that, you need to run force install warnings::register --or-- install R/RJ/RJBS/perl-5.24.0.tar.gz Running make test Can't test without successful make Running make install Make had returned bad status, install seems impossible Could not read '/home/avz/.cpan/build/Mouse-v2.4.5-gtPyV1/META.yml'. Falling back to other methods to determine prerequisites Could not read '/home/avz/.cpan/build/Crypt-SSLeay-0.72-ypNjbf/META.yml'. Falling back to other methods to determine prerequisites Could not read '/home/avz/.cpan/build/DateTime-TimeZone-Local-Win32-1.94-knZrvf/META.yml'. Falling back to other methods to determine prerequisites Could not read '/home/avz/.cpan/build/GD-2.56-KfYkXO/META.yml'. Falling back to other methods to determine prerequisites Could not read '/home/avz/.cpan/build/multidimensional-0.012-GF5S2z/META.yml'. Falling back to other methods to determine prerequisites Could not read '/home/avz/.cpan/build/bareword-filehandles-0.004-AL8LD9/META.yml'. Falling back to other methods to determine prerequisites Could not read '/home/avz/.cpan/build/GD-2.53-R0PZ76/META.yml'. Falling back to other methods to determine prerequisite
И хотя, на первый взгляд, все эти "Can't test", "Could not make: Unknown error" и "Could not read" выглядят весьма депрессивно, на деле оказалось, что появился некоторый прогресс. Так, теперь вместо сообщений об ошибках процесс установки модуля Server::Starter тупо зависал с сообщением "received TERM, sending TERM to all workers:1125" на консоли:
t/04-starter-dir.t ..... ok t/05-killolddelay.t .... start_server (pid:1038) starting now... starting new worker 1039 t/05-killolddelay.t .... 5/28 received HUP, spawning a new worker starting new worker 1125 new worker is now running, sending TERM to old workers:1039 sleeping 3 secs before killing old workers t/05-killolddelay.t .... 6/28 killing old workers old worker 1039 died, status:0 t/05-killolddelay.t .... 7/28 received TERM, sending TERM to all workers:1125 ^C KAZUHO/Server-Starter-0.32.tar.gz ./Build test -- NOT OK //hint// to see the cpan-testers results for installing this module, try: reports KAZUHO/Server-Starter-0.32.tar.gz Failed during this command: KAZUHO/Server-Starter-0.32.tar.gz : make_test NO
Спустя минут 5 созерцания этой красоты у меня сложилось впечатление, что это таки делает мне нервы, и нажал Ctrl-C. Так как тут речь идет о выполнении каких-то тестов, решил попробовать запустить в CPAN-shell вместо "install Server::Starter" команду "notest install Server::Starter". И шо вы думаете? Таки помогло!
cpan[5]> notest install Server::Starter Running install for module 'Server::Starter' KAZUHO/Server-Starter-0.32.tar.gz Has already been unwrapped into directory /home/avz/.cpan/build/Server-Starter-0.32-0 KAZUHO/Server-Starter-0.32.tar.gz Has already been prepared KAZUHO/Server-Starter-0.32.tar.gz Has already been made KAZUHO/Server-Starter-0.32.tar.gz Skipping test because of notest pragma Running Build install Building Server-Starter Installing /usr/local/share/man/man1/start_server.1 Installing /usr/local/share/perl5/Server/Starter.pm Installing /usr/local/share/perl5/Server/Starter/Guard.pm Installing /usr/local/share/man/man3/Server::Starter.3pm Installing /usr/local/bin/start_server KAZUHO/Server-Starter-0.32.tar.gz ./Build install -- OK
Ну а далее perl -MCPAN -e shell далее все четыре недостающих модуля установил без сучка и задоринки и взору предстала вожделенная картина:
# perl sbin/rt-test-dependencies perl: >=5.10.1(5.10.1) ...found users: rt group (rt) ...found bin owner (root) ...found libs owner (root) ...found libs group (bin) ...found web owner (apache) ...found web group (apache) ...found CLI dependencies: CORE dependencies: DASHBOARDS dependencies: GD dependencies: GPG dependencies: GRAPHVIZ dependencies: ICAL dependencies: MAILGATE dependencies: SMIME dependencies: USERLOGO dependencies: All dependencies have been found.
Перемога!
rev="post-1654" No comments
– 03.10.2016
Оказывается, не все в курсе, что для карты "универсальная" (раньше она называлась "кредитка универсальная") от приватбанка можно включить начисление процентов на остаток.
1. Выбираем нужную карту в списке карт слева и переходим в её настройки, кликая по ссылке "управление картой/счетом":
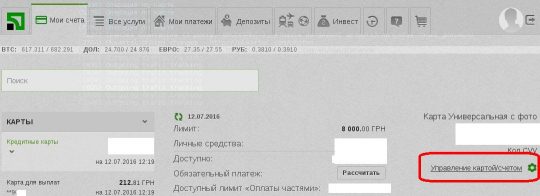
Универсалка - включаем начисление процентов на остаток
2. Если депозитное свойство не активировано, то включаем его:
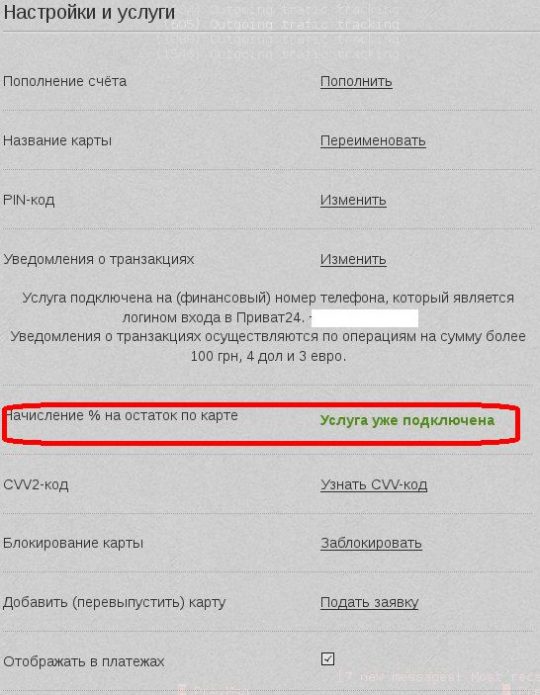
Что сделать чтобы капали проценты по универсальной
Всё. В результате получаем примерно 10% годовых от остатка на бонусный счет. Средства с бонусного счета можно тратить в торговых точках c наклейками "бонус-плюс". Полный их список есть на официальном сайте.
Posted in Money.
rev="post-1643" 1 comment
– 12.07.2016
Иногда возникает необходимость прибить какое-то TCP-соединение. Часто для решения этой задачи с помощью lsof или netstat вычисляют процесс, который это соединение обслуживает и что-то с этим процессом делают (например, kill -9). Но вот для ситуации когда процесс найти не получается (например, он завершился аварийно и не закрыл после себя соединение) или прибивать процесс нельзя, уже задачка становиться не совсем тривиальной.
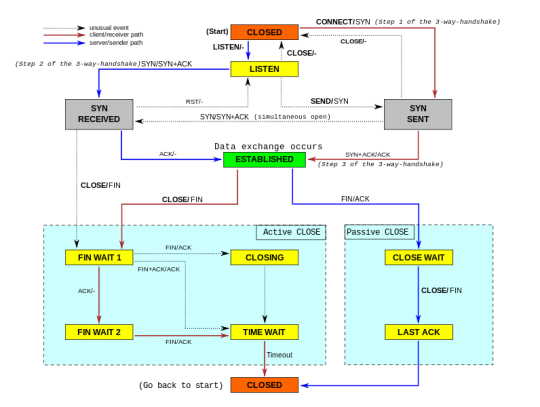
Состояния TCP-соединения и переходы между ними
Тут может пригодится perl-утилитка под названием killcx, которая должна помочь и в случае когда TCP-соединение пребывает в состоянии TIME_WAIT. Работает примерно так:
# ./killcx 10.11.12.13:44034 killcx v1.0.3 - (c)2009-2011 Jerome Bruandet - http://killcx.sourceforge.net/ [PARENT] checking connection with [10.11.12.13:44034] [PARENT] found connection with [10.10.10.10:22] (ESTABLISHED) [PARENT] forking child [PARENT] sending spoofed SYN to [10.10.10.10:22] with bogus SeqNum [CHILD] interface not defined, will use [eth0] [CHILD] setting up filter to sniff ACK on [eth0] for 5 seconds f[CHILD] hooked ACK from [10.10.10.10:22] [CHILD] found AckNum [1240626855] and SeqNum [301466544] [CHILD] sending spoofed RST to [10.10.10.10:22] with SeqNum [1240626855] [CHILD] sending RST to remote host as well with SeqNum [301466544] [CHILD] all done, sending USR1 signal to parent [19312] and exiting [PARENT] received child signal, checking results... => success : connection has been closed !
В качестве аргумента ей нужно передать IP-адрес и порт удаленной стороны TCP-соединения. В этом примере я подключился по SSH с клиента 10.11.12.13 на сервер с адресом 10.10.10.10. Команда выполнялась на сервере 10.10.10.10.
Для работы утилита требует наличия следующих perl-модулей:
* Net::RawIP (для создания spoofed packets, CPAN-ом он у меня просто так ставиться не захотел, жалуясь на тесты, пришлось сделать force install Net::RawIP)
* Net::Pcap (для перехвата TCP-пакетов).
* NetPacket::Ethernet (для декодирования TCP/IP-пакетов).
Также может потребоваться предварительная установка пакета libpcap-devel.
Также с похожей функциональностью есть утилита cutter. Но она работает только в случае, если запускается на промежуточном между клиентом и сервером роутере.
Попытка оборвать соединения с сервисом, запущенном на порту 62616 сервера 10.10.10.10, с клиента 10.20.20.20:
[root@avz /tmp/cutter-1.04]# ./cutter 10.10.10.10 62616 10.20.20.20 Error: The matching connection terminates on THIS computer. Note: cutter can only cut connections running over the router or firewall on which it is run. It cannot cut connections that terminate locally. So: you should run cutter on the firewall/router, not on the client or server machine.
Что, в принципе, было ожидаемо. На роутере я ее пока запускать не пробовал.
Ещё есть третий вариант принудительного завершения TCP-соединения - использование утилиты tcpkill. Её преимущество в том, что ее намного проще установить (по сравнению с killcx) – достаточно просто установить пакет dsniff, в состав которого она входит. Какое именно соединение обрывать ей нужно указать с помощью BPF-выражения, формат которых знаком каждому, кто пользовался tcpdump-ом.
Пример использования:
[root@srv ~]# lsof -i -nP | grep ssh sshd 1805 root 3u IPv4 14341 0t0 TCP *:22 (LISTEN) sshd 1805 root 4u IPv6 14345 0t0 TCP *:22 (LISTEN) sshd 9832 root 3r IPv4 15780961 0t0 TCP 192.168.1.1:5224->192.168.1.51:34749 (ESTABLISHED) sshd 9835 avz 3u IPv4 15780961 0t0 TCP 192.168.1.1:5224->192.168.1.51:34749 (ESTABLISHED) [root@srv ~]# tcpkill -i eth1.2 host 192.168.1.51 and port 34749 tcpkill: listening on eth1.2 [host 192.168.1.51 and port 34749] Write failed: Broken pipe
Здесь я подключился по SSH с хоста 192.168.1.51 на сервер 192.168.1.1 и запустил сначала команду lsof чтобы узнать порт на стороне клиента (34749). Затем передал его в качестве аргумента tcpkill-у и соединение сразу было разорвано. Следует учитывать, что tcpkill сработает только для соединения, по которому передаются хоть какие-то данные. В противном случае он просто будет висеть в ожидании следующей порции трафика.
Еще один, пожалуй, самый изящный вариант с использованием отладчика gdb. Опять поключаемся по SSH с 192.168.1.51 на 192.168.1.1 и что-то там запускаем для красоты, например такой цикл:
[user@avz ~]$ ssh 192.168.1.1 Last login: Sat Aug 26 23:13:00 2017 from 192.168.1.51 [user@srv ~]$ for i in {1..100} ; do date ; sleep 1 ; done Sat Aug 26 23:25:35 EEST 2017 Sat Aug 26 23:25:36 EEST 2017 Sat Aug 26 23:25:37 EEST 2017 Sat Aug 26 23:25:38 EEST 2017 Sat Aug 26 23:25:39 EEST 2017
В соседней консоли смотрим информацию о только что установленном соединении:
[root@avz]# lsof -i -nP | grep ssh | grep 192.168.1.1:22 ssh 19543 avz 3u IPv4 830283369 0t0 TCP 192.168.1.51:37527->192.168.1.1:22 (ESTABLISHED)
Получаем PID (19543) и номер файлового дескриптора (3, см. 4-ое поле). Далее запускаем gdb и командой close говорим ему закрыть файловый дескриптор с номером 3:
[root@avz]# gdb -p 19543 (gdb) call close(3) $1 = 0 (gdb) quit A debugging session is active. Inferior 1 [process 19543] will be detached. Quit anyway? (y or n) y Detaching from program: /usr/bin/ssh, process 19543
Возвращаемся в первую консоль и видим там, что соединение было разорвано:
Sat Aug 26 23:25:40 EEST 2017 Sat Aug 26 23:25:41 EEST 2017 Sat Aug 26 23:25:42 EEST 2017 Sat Aug 26 23:25:43 EEST 2017 Sat Aug 26 23:25:44 EEST 2017 Sat Aug 26 23:25:45 EEST 2017 Sat Aug 26 23:25:46 EEST 2017 Sat Aug 26 23:25:47 EEST 2017 Sat Aug 26 23:25:48 EEST 2017 Write failed: Bad file descriptor [user@avz ~]$
Также есть другой вариант избавиться от TIME-WAIT-ов, из разряда "из пушки по воробьям" – просто рестартануть сеть (service network restart или что там в Вашем дистрибутиве аналогичное).
А вот чтобы не доводить вообще до появления TIME-WAIT-ов или снизить их количество, может помочь установка следующих опций ядра:
net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1
При чем для net.ipv4.tcp_tw_recycle следует помнить, что ее включение может поломать работу клиентов за NAT-ом и в общем случае включать ее не рекомендуется.
А вот для закрытия соединений в состоянии CLOSE_WAIT может пригодится вот эта штука: https://github.com/rghose/kill-close-wait-connections или свежие версии штатной утилиты ss из пакета iproute:
ss --tcp state CLOSE-WAIT '( dport = 22 or dst 1.1.1.1 )' --kill
rev="post-1641" 1 comment
– 05.07.2016
